

This post was contributed by Shape Immersive Managing Partner Alex Chuang, originally appearing in AR/VR Journey.
Reality Check: The marvel of computer vision technology in today’s camera-based AR systems
How does mobile AR work today and how will it work tomorrow
by Alex Chuang

British science fiction writer, Sir Arthur C. Clark, once said, “Any sufficiently advanced technology is indistinguishable from magic.”
Augmented reality has the potential to instill awe and wonder in us just as magic would. For the very first time in the history of computing, we now have the ability to blur the line between the physical world and the virtual world. AR promises to bring forth the dawn of a new creative economy, where digital media can be brought to life and given the ability to interact with the real world.
AR experiences can seem magical but what exactly is happening behind the curtain? To answer this, we must look at the three basic foundations of a camera-based AR system like our smartphone.
- How do computers know where it is in the world? (Localization + Mapping)
- How do computers understand what the world looks like? (Geometry)
- How do computers understand the world as we do? (Semantics)
Part 1: How do computers know where it is in the world? (Localization)

When NASA scientists put the rover onto Mars, they needed a way for the robot to navigate itself on a different planet without the use of a global positioning system (GPS). They came up with a technique called Visual Inertial Odometry (VIO) to track the rover’s movement over time without GPS. This is the same technique that our smartphones use to track their spatial position and orientation.
A VIO system is made out of two parts.
- The Optical System
- The Inertial System or Inertial Measurement Unit (IMU)
The optical system is comprised of a camera stack which includes the lens, shutter and image sensors. The inertial system is made up of an accelerometer, which measures acceleration and a gyroscope, which measures orientation. Together, they help your device determine its position (x, y, z) and orientation (pitch, yaw, roll), which is also known as your 6-degrees-of-freedom (6DoF) pose.
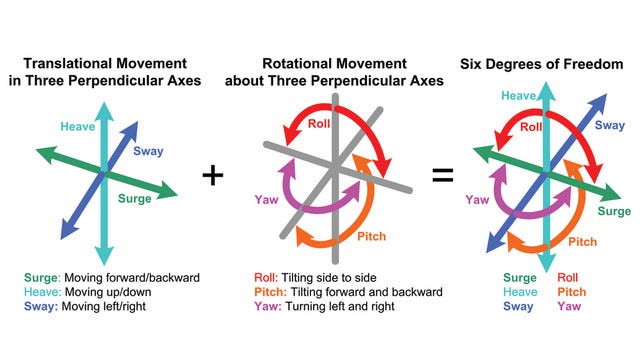
As you move your smartphone to look at the AR content, your phone is essentially capturing many photos of the environment and comparing them to figure out its position. For each photo it captures, it is also identifying key features in the environment that are visually unique and interesting in nature such as the edges, corners, ridges of unique objects in the scene. By comparing two images and their respective key features and using the sensor data from the phone’s IMU, your phone can figure out its position through stereoscopic calculation. It’s very similar to how our eyes can infer depth.

How does mapping work?
When I am lost in a foreign city, the first thing I do is open my Google Maps and look around for visual clues (landmarks, Starbucks, road signs, etc.) to figure out where I am on the map.
For your phone to understand where it is in space, it needs to first build and memorize a map of its surrounding by “looking” around. This machine-readable map is basically a graph of all the interesting points that your phone identified including their descriptions (e.g. colors and lighting). Together, these points or features form a sparse point cloud that looks like the gif below.
This map is very important for your phone to relocalize itself when it loses tracking. Your phone can lose tracking if you cover the camera, drop your phone or move your phone too fast and it’s capturing blurry images. When these scenarios happen, your phone will need to relocalize itself. The relocalization process starts when your phone looks at the scene again and identifies the key features of the scene. It then compares those features with the features on the map it previously memorized. When a match has been found, it will be able to find its spatial position again.
What is SLAM (Simultaneous Localization and Mapping)?
To bring everything together, SLAM refers to the broader system that allows your phone to construct and update a map of an unknown environment while simultaneously keep track of its location within the map. SLAM systems include subsystems that we already mentioned like the phone’s optical systems, inertial systems, and mapping systems. Through tight integration between hardware and software, your phone now has this incredible ability to understand where it is in the world and track itself within its environment.
Why isn’t GPS good enough?
GPS will be able to give you a rough estimate of your latitude and longitude position in the world, but it is not accurate enough to give you your precise location. Also, GPS doesn’t work in many underground or indoor environments because the signal from the satellites weakens or distorts as it travels through solid material.
Part 2: How do computers understand what the world looks like? (Geometry)
When Pokemon Go first took the world by storm in 2016, we were charmed by the iconic yellow furry monster that we can see in the real world. However, we quickly realized that Pikachu did not have a clue what the world looked like. To our disappointment, Pikachu was simply a computer-generated graphic that was overlayed on top of the real world.
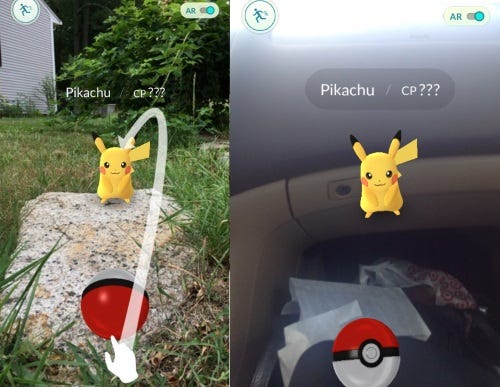
Fast forward to 2019, your phone now has an incredible ability to map your environment spatially (3D reconstruction) with the help of 6D.ai’s software. This means it can understand the shape or structure of real objects in the scene, making occlusion and collision possible. Occlusion is the ability for virtual objects to hide behind real-world objects. And collision is the ability for virtual objects to collide with real-world objects. When virtual objects respond to real-world physics as if they are real, this makes the AR experience so much more believable.
6d.ai is making huge technological advancement in the field of 3D reconstruction for mobile phones. Through their software, the monocular RGB camera on your phone now possesses the power of a depth sensor. It can scan the environment and capture a dense point cloud, which is later converted into a mesh through computational geometry.
Think of a mesh like a thin invisible blanket that drapes over the scene, outlining the external surface of objects. As you move your phone around, this mesh is updated in real-time, providing your device with the most accurate spatial understanding of your physical environment. With this new information, the virtual Pikachu can hop on to your couch, go under a table, and run behind your kitchen counter.
In this demo below, we used 6D.ai to rapidly generate a textured 3D mesh of the physical environment and allow virtual alien plants to grow on the surfaces of walls, floors, and tables.
Through the lens of our camera, we can now step into a magical alternate dimension that is parallel to our world, just like “The Upside Down” in Stranger Things.
Part 3: How can computers understand the world as we do? (Semantics)
Cuteness alert! Tell me what do you see in the following photo?

Some of you might say that you see 2 dogs and 2 cats. Some of you might say you see 2 puppies and 2 kittens. And for those of you who are really good, you would say you spot 2 Dachshund puppies and 2 Russian Blue kittens.
When computers see this image, all they see is a bunch of 1’s and 0’s. But with a convolutional neural network (CNN) model, computers can be trained to localize, detect, classify and segment objects. At the simplest level, a convolutional neural network is a system that takes a source image like the one above and figure out the different patterns that it sees in the photo through a series of specialized layers. Each layer has filters that are trained to recognize a specific pattern like edges, shapes, textures, corners or even sophisticated objects like dogs, cats, humans, cars or stop signs.
With CNN as the backbone, the computer can now perform other computer vision tasks such as object detection and classification, semantic segmentation, and instance segmentation.
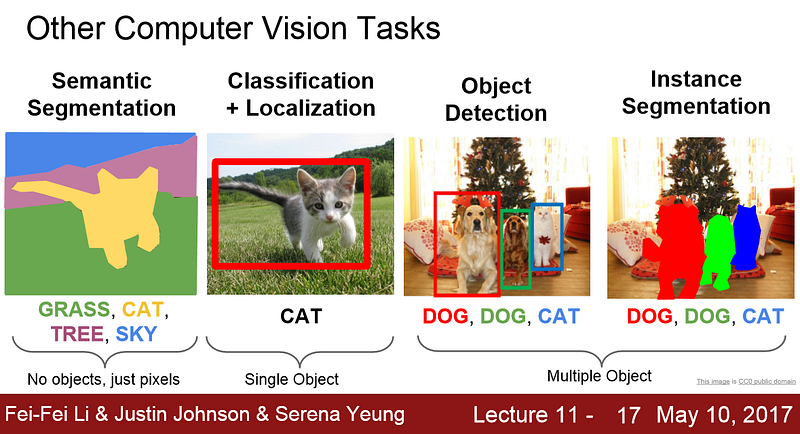
Object Detection + Classification
Object detection and classification is the process of drawing a bounding box around the object(s) in the image and giving it a class label such as dog, cat, person etc. There are two types of algorithms to consider:
- Algorithms based on classification work in two stages. In the first step, the model selects an interesting region and then it attempts to classify those regions using CNN. Predictions are ran for every selected region until the CNN model is confident that it has detected the object that it is looking for. This is a computationally expensive method because you’re essentially processing the entire image to look for one thing.
- Algorithms based on regression predicts classes and bounding boxes for the whole image in one run of the algorithm. The most well-known example of this type of algorithms is YOLO (You only look once), which iscommonly used for real-time object detection.
Semantic Segmentation
Semantic segmentation is a process that aims to recognize and understand what’s in the image at the pixel level. Each pixel of the image is associated with a class label such as grass, cat, tree, and sky. Each class label is also highlighted by a unique color.

However, semantic segmentation does not highlight individual instances of a class differently. For example, if there are 2 cows in the photo, it will highlight the collective area of the 2 cows and we won’t be able to distinguish one cow from another. This is where instance segmentation comes into play.
Instance Segmentation
Instance segmentation is actually a combo method of object detection and semantic segmentation. First, the model will use object detection to draw a bounding box around each of the two dogs. Then it will perform semantic segmentation within the bounding box to segment out the instances.

This particular model is called Mask R-CNN (mask regional convolutional neural network), which was built by the Facebook AI research team in 2017.
Can Mask R-CNN be used in real-time for Augmented Reality?
The short answer is yes, but there is a trade-off in quality and speed. Niantic used a similar deep neural network to infer 3D information about the surrounding world so perceived occlusion can be possible. In the demo below, it is quite obvious that dynamic objects like humans are segmented and masked in real-time so Pikachu and Eevee can run behind them.
Here is another example of how real-time instance segmentation is applied to let you virtually try on new hair color.
https://youtu.be/HIqOgxx-zdQ
And here is a demo of a context-aware AR shooting game. The neural network is able to identify the different objects in the scene as well as its material (e.g. wood, glass, fabric). As a result, when the virtual bullet passes through each material, a different animation effect takes place. For example, when the bullet passes through the fabric chair, feathers exploded out.
What does all of this mean for the future of Augmented Reality?
As computers learn to localize itself, see and understand the world as we do, we are one step closer to merging the virtual and physical world.
One day, we will create a machine-readable, 1:1 scale model of the world known as “The AR Cloud”. The AR Cloud has many alternative names such as “the world’s digital twin”, “the mirror world” or “magicverse”. Personally, I’d like to think of it as a digital replica of our world that perfectly overlays on top of our real world.
“The AR Cloud is going to become the single most important software infrastructure in the history of computing, far bigger than Facebook’s Social Graph or Google’s Search Index.”- Ori Inbar, Super Ventures
Not only will The AR Cloud enable everyone to have a shared experience, but its applications also extend well into self-driving cars, Internet of Things, automation, smart cities or self-navigating delivery drones.
Soon we will be able to program context-aware media to interact with our real world. In 2015, Niantic released a Pokemon Go concept trailer where they showed hundreds of people using their Pokemons to fight Mewtwo in Timesquare. This type of experience will be possible as key technologies such as The AR Cloud, 5G, AI and AR glasses mature over time.
JK Rowling once said, “We do not need magic to change the world, we carry all the power we need inside ourselves already: we have the power to imagine better.” With augmented reality, our world becomes a canvas for us to paint our imagination over. Hopefully, this article was able to inspire you to experiment and create with AR!
For deeper XR data and intelligence, join ARtillery PRO and subscribe to the free AR Insider Weekly newsletter.
Disclosure: AR Insider has no financial stake in the companies mentioned in this post, nor received payment for its production. Disclosure and ethics policy can be seen here.
Header image credit: Google